Meta, 최첨단 멀티모달 모델인 Chameleon 출시

컨텐츠 정보
- 891 조회
본문

생성 AI 분야의 경쟁이 다중 모드 모델로 전환됨에 따라 Meta는 프론티어 연구소에서 출시한 모델에 대한 답변이 무엇인지에 대한 미리 보기를 공개했습니다. 새로운 모델 제품군인 Chameleon은 다양한 양식의 구성 요소를 결합하는 대신 기본적으로 다중 모드로 설계되었습니다.
Meta는 아직 모델을 출시하지 않았지만 보고된 실험에 따르면 Chameleon은 이미지 캡션 및 VQA(시각적 질문 답변)를 포함한 다양한 작업에서 최첨단 성능을 달성하는 동시에 텍스트 전용 작업에서는 경쟁력을 유지하는 것으로 나타났습니다.
조기 융합 다중 모드 모델
다중 모드 기반 모델을 생성하는 인기 있는 방법은 다양한 양식에 대해 훈련된 모델을 함께 패치하는 것입니다. 이러한 접근 방식을 AI 시스템이 다양한 양식을 수신하고 이를 별도의 모델로 인코딩한 다음 추론을 위해 인코딩을 융합하는 "후기 융합"이라고 합니다. 후기 융합은 잘 작동하지만 양식 전반에 걸쳐 정보를 통합하고 인터리브된 이미지와 텍스트의 시퀀스를 생성하는 모델의 기능을 제한합니다.
카멜레온은 "초기 융합 토큰 기반 혼합 모달" 아키텍처를 사용합니다. 즉, 이미지, 텍스트, 코드 및 기타 양식의 인터리브 혼합에서 학습하도록 처음부터 설계되었음을 의미합니다. 카멜레온은 언어 모델이 단어를 사용하는 것처럼 이미지를 개별 토큰으로 변환합니다. 또한 텍스트, 코드, 이미지 토큰으로 구성된 통합 어휘를 사용합니다. 이를 통해 이미지와 텍스트 토큰을 모두 포함하는 시퀀스에 동일한 변환기 아키텍처를 적용할 수 있습니다.
연구원에 따르면 Chameleon과 가장 유사한 모델은 초기 융합 토큰 기반 접근 방식을 사용하는 Google Gemini 입니다. 하지만 Gemini는 생성 단계에서 별도의 이미지 디코더를 사용하는 반면, Chameleon은 토큰을 처리하고 생성하는 엔드투엔드 모델입니다.
연구원들은 “Chameleon의 통합 토큰 공간을 통해 양식별 구성 요소 없이도 인터리브된 이미지와 텍스트 시퀀스를 원활하게 추론하고 생성할 수 있습니다.”라고 썼습니다.
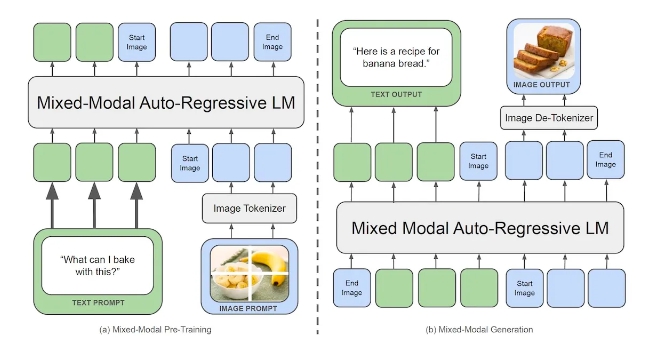
Met Chameleon 인코딩 및 디코딩 로직(출처: arxiv )
초기 융합은 매우 매력적이지만 모델을 훈련하고 확장할 때 상당한 어려움을 안겨줍니다. 이러한 과제를 극복하기 위해 연구원들은 일련의 아키텍처 수정 및 교육 기술을 사용했습니다. 논문에서 그들은 다양한 실험과 그것이 모델에 미치는 영향에 대한 세부 정보를 공유합니다.
카멜레온의 훈련은 4조 4천억 개의 텍스트 토큰, 이미지-텍스트 쌍, 인터리브된 텍스트 및 이미지 시퀀스를 포함하는 데이터 세트를 사용하여 두 단계로 진행됩니다. 연구원들은 500만 시간이 넘는 Nvidia A100 80GB GPU 에서 70억 및 340억 매개변수 버전의 Chameleon을 훈련시켰습니다 .
활동 중인 카멜레온
논문에 보고된 실험에 따르면 카멜레온은 다양한 텍스트 전용 작업과 다중 모드 작업을 수행할 수 있습니다. VQA(시각적 질문 답변) 및 이미지 캡션 벤치마크에서 Chameleon-34B는 Flamingo, IDEFICS 및 Llava-1.5 와 같은 모델을 능가하는 최첨단 성능을 달성했습니다 .
연구원에 따르면 Chameleon은 "사전 훈련된 모델 평가와 미세 조정된 모델 평가 모두에서 훨씬 적은 수의 상황 내 훈련 예제와 더 작은 모델 크기"를 사용하여 다른 모델의 성능을 일치시킵니다.
다중 양식의 단점 중 하나는 단일 양식 요청의 성능 저하입니다. 예를 들어 비전 언어 모델은 텍스트 전용 프롬프트에서 성능이 낮은 경향이 있습니다. 그러나 Chameleon은 상식 추론 및 독해 작업에서 Mixtral 8x7B 및 Gemini-Pro와 같은 모델과 일치하는 텍스트 전용 벤치마크에서 여전히 경쟁력을 유지하고 있습니다.
흥미롭게도 Chameleon은 혼합 모드 추론 및 생성을 위한 새로운 기능을 잠금 해제할 수 있습니다. 특히 프롬프트가 텍스트와 이미지가 인터리브된 혼합 모드 응답을 기대할 때 더욱 그렇습니다. 사람이 평가한 응답을 사용한 실험에서는 전반적으로 사용자가 Chameleon에서 생성된 다중 모드 문서를 선호하는 것으로 나타났습니다.
지난주 OpenAI 와 Google은 풍부한 다중 모드 경험을 제공하는 새로운 모델을 공개했습니다. 그러나 그들은 모델에 대한 자세한 내용을 공개하지 않았습니다. Meta가 계속해서 플레이북을 따르고 Chameleon의 가중치를 공개한다면 개인 모델에 대한 개방형 대안이 될 수 있습니다.
조기 융합은 또한 특히 더 많은 양식이 혼합에 추가됨에 따라 고급 모델에 대한 연구에 대한 새로운 방향을 제시할 수 있습니다. 예를 들어, 로봇 공학 스타트업은 이미 언어 모델을 로봇 제어 시스템에 통합하는 실험을 진행하고 있습니다 . 초기 융합이 로봇 공학 기반 모델을 어떻게 개선할 수 있는지 보는 것도 흥미로울 것입니다.
연구원들은 "카멜레온은 유연하게 추론하고 다중 모드 콘텐츠를 생성할 수 있는 통합 기반 모델의 비전을 실현하기 위한 중요한 단계를 나타냅니다."라고 썼습니다.






